
October 10, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Martin Nowak | On 10/9/13 6:10 PM, Martin Nowak wrote:
> On 10/08/2013 05:05 PM, Andrei Alexandrescu wrote:
>> But no matter. My most significant bit is, we need a trie lexer
>> generator ONLY from the token strings, no TK_XXX user-provided symbols
>> necessary. If all we need is one language (D) this is a non-issue
>> because the library writer provides the token definitions. If we need to
>> support user-provided languages, having the library manage the string ->
>> small integer mapping becomes essential.
>
> It's good to get rid of the symbol names.
> You should try to map the strings onto an enum so that final switch works.
>
> final switch (t.type_)
> {
> case t!"<<": break;
> // ...
> }
Excellent point! In fact one would need to use t!"<<".id instead of t!"<<".
I'll work on that next.
Andrei
| |||
 Permalink
Permalink Reply
ReplyOctober 10, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Andrei Alexandrescu | On Thursday, 10 October 2013 at 17:34:01 UTC, Andrei Alexandrescu wrote:
> Excellent point! In fact one would need to use t!"<<".id instead of t!"<<".
>
> I'll work on that next.
>
>
> Andrei
I don't suppose this new lexer is on Github or something. I'd like to help get this new implementation up and running.
| |||
October 11, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
Posted in reply to Brian Schott | On 10/10/13 2:41 PM, Brian Schott wrote:
> On Thursday, 10 October 2013 at 17:34:01 UTC, Andrei Alexandrescu wrote:
>> Excellent point! In fact one would need to use t!"<<".id instead of
>> t!"<<".
>>
>> I'll work on that next.
>>
>>
>> Andrei
>
> I don't suppose this new lexer is on Github or something. I'd like to
> help get this new implementation up and running.
Thanks for your gracious comeback. I was fearing a "My work is not appreciated, I'm not trying to contribute anymore" etc.
The code is part of Facebook's project that I mentioned in the announce forum. I am attempting to open source it, should have an answer soon.
Andrei
| |||
October 11, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Andrei Alexandrescu | On 10/10/2013 07:34 PM, Andrei Alexandrescu wrote: > Excellent point! In fact one would need to use t!"<<".id instead of t!"<<" Either adding an alias this from TokenType to the enum or returning the enum in tk!"<<" would circumvent this. See http://dpaste.dzfl.pl/cdcba00d | |||
October 11, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Walter Bright | > 3. This level of abstraction combined with efficient generation cannot be currently done in any other language.
>
This is wrong.
| |||
October 11, 2013 Re: std.d.lexer performance (WAS: std.d.lexer : voting thread) | ||||
|---|---|---|---|---|
| ||||
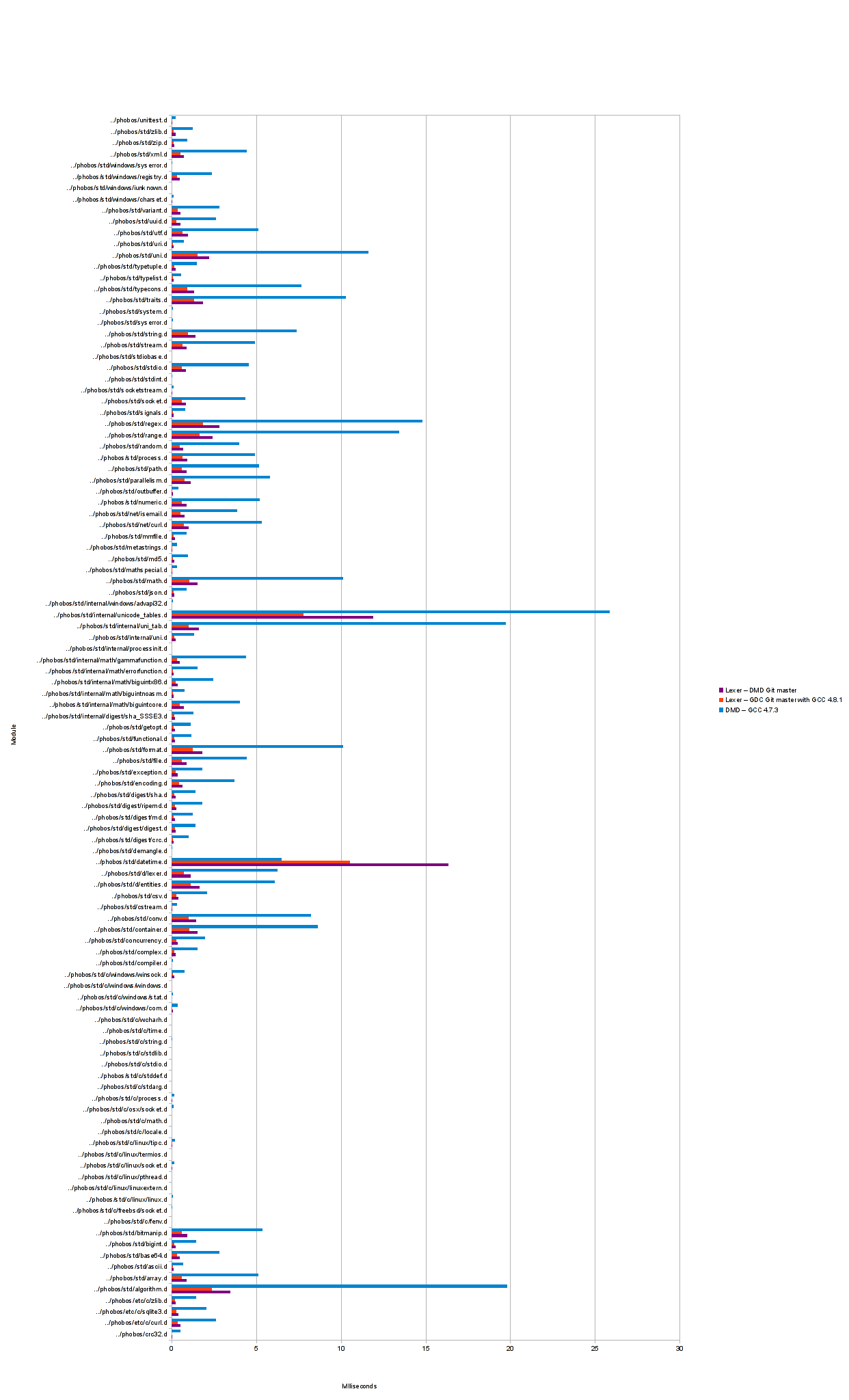
 Posted in reply to Brian Schott | 04-Oct-2013 15:28, Brian Schott пишет: > On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote: >> I see we're considerably behind dmd. If improving performance would >> come at the price of changing the API, it may be sensible to hold off >> adoption for a bit. >> >> Andrei > > The old benchmarks measured total program run time. I ran a new set of > benchmarks, placing stopwatch calls around just the lexing code to > bypass any slowness caused by druntime startup. I also made a similar > modification to DMD. > > Here's the result: > > https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times5.png > > > I suspect that I've made an error in the benchmarking due to how much > faster std.d.lexer is than DMD now, so I've uploaded what I have to Github. > > https://github.com/Hackerpilot/lexerbenchmark I'm suspicious of: printf("%s\t%f\n", srcname, (total / 200.0) / (1000 * 100)); Plus I think clock_gettime often has too coarse resolution (I'd use gettimeofday as more reliable). Also check core\time.d TickDuration.currSystemTick as it uses CLOCK_MONOTONIC on *nix. You should do the same to make timings meaningful. -- Dmitry Olshansky | |||
{kind=link}
October 11, 2013 Re: std.d.lexer performance (WAS: std.d.lexer : voting thread) | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Dmitry Olshansky | On Friday, October 11, 2013 12:56:14 Dmitry Olshansky wrote:
> 04-Oct-2013 15:28, Brian Schott пишет:
> > On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote:
> >> I see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit.
> >>
> >> Andrei
> >
> > The old benchmarks measured total program run time. I ran a new set of benchmarks, placing stopwatch calls around just the lexing code to bypass any slowness caused by druntime startup. I also made a similar modification to DMD.
> >
> > Here's the result:
> >
> > https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimen tal/std_lexer/images/times5.png
> >
> >
> > I suspect that I've made an error in the benchmarking due to how much faster std.d.lexer is than DMD now, so I've uploaded what I have to Github.
> >
> > https://github.com/Hackerpilot/lexerbenchmark
>
> I'm suspicious of:
> printf("%s\t%f\n", srcname, (total / 200.0) / (1000 * 100));
>
> Plus I think clock_gettime often has too coarse resolution (I'd use
> gettimeofday as more reliable).
> Also check core\time.d TickDuration.currSystemTick as it uses
> CLOCK_MONOTONIC on *nix. You should do the same to make timings meaningful.
Why not just use use std.datetime's benchmark or StopWatch? Though looking at lexerbenchmark.d it looks like he's using StopWatch rather than clock_gettime directly, and there are no printfs, so I don't know what code you're referring to here. From the looks of it though, he's basically reimplemented std.datetime.benchmark in benchmarklexer.d and probably should have just used benchmark instead.
- Jonathan M Davis
| |||
October 11, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
Posted in reply to Andrei Alexandrescu | 06-Oct-2013 20:07, Andrei Alexandrescu пишет: > On 10/6/13 5:40 AM, Joseph Rushton Wakeling wrote: >> How quickly do you think this vision could be realized? If soon, I'd say >> it's worth delaying a decision on the current proposed lexer, if not ... >> well, jam tomorrow, perfect is the enemy of good, and all that ... > > I'm working on related code, and got all the way there in one day > (Friday) with a C++ tokenizer for linting purposes (doesn't open > #includes or expand #defines etc; it wasn't meant to). > > The core generated fragment that does the matching is at > https://dpaste.de/GZY3. > > The surrounding switch statement (also in library code) handles > whitespace and line counting. The client code needs to handle by hand > things like parsing numbers (note how the matcher stops upon the first > digit), identifiers, comments (matcher stops upon detecting "//" or > "/*") etc. Such things can be achieved with hand-written code (as I do), > other similar tokenizers, DFAs, etc. The point is that the core loop > that looks at every character looking for a lexeme is fast. This is something I agree with. I'd call that loop the "dispatcher loop" in a sense that it detects the kind of stuff and forwards to a special hot loop for that case (if any, e.g. skipping comments). BTW it absolutely must be able to do so in one step, the generated code already knows that the token is tok!"//" hence it may call proper handler right there. case '/': ... switch(s[1]){ ... case '/': // it's a pseudo token anyway so instead of //t = tok!"//"; // just _handle_ it! t = hookFor!"//"(); //user hook for pseudo-token // eats whitespace & returns tok!"comment" or some such // if need be break token_scan; } This also helps to get not only "raw" tokens but allow user to cook extra tokens by hand for special cases that can't be handled by "dispatcher loop". > > > Andrei > -- Dmitry Olshansky | |||
October 11, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
Posted in reply to Andrei Alexandrescu | 08-Oct-2013 04:16, Andrei Alexandrescu пишет: > On 10/4/13 5:24 PM, Andrei Alexandrescu wrote: > To put my money where my mouth is, I have a proof-of-concept tokenizer > for C++ in working state. > > http://dpaste.dzfl.pl/d07dd46d > > It contains some rather unsavory bits (I'm sure a ctRegex would be nicer > for parsing numbers etc), but it works on a lot of code just swell. No - ctRegex as it stands right now is too generic and conservative with the code it generates so "\d+" would do: a) use full Unicode for "Number" b) keep tabs on where to return as if there could be ambiguity of how many '\d' it may eat (no maximal munch etc.). The reason is that the fact that said '\d+' may be in the middle of some pattern (e.g. 9\d+0), and the fact that it's unambiguous on its own is not exploited. Both are quite suboptimal and there is a long road I going to take to have a _general_ solution for both points. One day we would reach that goal though. ATM just hack your way through if pattern is sooo simple. > Most importantly, there's a clear distinction between the generic core > and the C++-specific part. It should be obvious how to use the generic > matcher for defining a D tokenizer. > Token representation is minimalistic and expressive. Just write tk!"<<" > for left shift, tk!"int" for int etc. Typos will be detected during > compilation. One does NOT need to define and use TK_LEFTSHIFT or TK_INT; > all needed by the generic tokenizer is the list of tokens. In return, it > offers an efficient trie-based matcher for all tokens. > > (Keyword matching is unusual in that keywords are first found by the > trie matcher, and then a simple check figures whether more characters > follow, e.g. "if" vs. "iffy". +1 Given that many tokenizers use a hashtable > anyway to look up all symbols, there's no net loss of speed with this > approach. Yup. The only benefit is slimmer giant switch. Another "hybrid" option is insated of hash-table use a generated keyword trie searcher separately as a function. Then just test each identifier with it. This is what std.d.lexer does and is quite fast. (awaiting latest benchmarks) > The lexer generator compiles fast and should run fast. If not, it should > be easy to improve at the matcher level. > > Now, what I'm asking for is that std.d.lexer builds on this design > instead of the traditional one. At a slight delay, we get the proverbial > fishing rod IN ADDITION TO of the equally proverbial fish, FOR FREE. It > is quite evident there's a bunch of code sharing going on already > between std.d.lexer and the proposed design, so it shouldn't be hard to > effect the adaptation. Agreed. Let us take a moment to incorporate a better design. > So with this I'm leaving it all within the hands of the submitter and > the review manager. I didn't count the votes, but we may have a "yes" > majority built up. Since additional evidence has been introduce, I > suggest at least a revote. Ideally, there would be enough motivation for > Brian to suspend the review and integrate the proposed design within > std.d.lexer. > > > Andrei > -- Dmitry Olshansky | |||
October 11, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
Posted in reply to Brian Schott | 11-Oct-2013 01:41, Brian Schott пишет: > On Thursday, 10 October 2013 at 17:34:01 UTC, Andrei Alexandrescu wrote: >> Excellent point! In fact one would need to use t!"<<".id instead of >> t!"<<". >> >> I'll work on that next. >> >> >> Andrei > > I don't suppose this new lexer is on Github or something. I'd like to > help get this new implementation up and running. Love this attitude! :) Having helped with std.d.lexer before (w.r.t. to performance mostly) I'm inclined to land a hand in perfecting the more generic one. -- Dmitry Olshansky | |||
Copyright © 1999-2021 by the D Language Foundation