
October 24, 2017 Re: My two cents | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Adam Wilson | On Monday, 23 October 2017 at 22:22:55 UTC, Adam Wilson wrote: > On 10/23/17 08:21, Kagamin wrote: >> [...] > > Actually I think it fits perfectly with D, not for reason of performance, but for reason of flexibility. D is a polyglot language, with by far the most number of methodologies supported in a single language that I've ever encountered. > > [...] There is a lot of misunderstanding about async/await. It has nothing to do with "conservation of thread resources" or trading "raw performance for an ability > to handle a truly massive number of simultaneous tasks". Async/await is just 'syntactic sugar' where the compiler re-writes your code into a state machine around APM (Asynchronous programming model which was introduced in .NET 2.0 sometime around 2002 I believe). That's all there is to it, it makes your asynchronous code look and feel synchronous. | |||
 Permalink
Permalink Reply
ReplyOctober 23, 2017 Re: My two cents | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to flamencofantasy | On 10/23/17 17:27, flamencofantasy wrote: > On Monday, 23 October 2017 at 22:22:55 UTC, Adam Wilson wrote: >> On 10/23/17 08:21, Kagamin wrote: >>> [...] >> >> Actually I think it fits perfectly with D, not for reason of >> performance, but for reason of flexibility. D is a polyglot language, >> with by far the most number of methodologies supported in a single >> language that I've ever encountered. >> >> [...] > > There is a lot of misunderstanding about async/await. It has nothing to > do with "conservation of thread resources" or trading "raw performance > for an ability >> to handle a truly massive number of simultaneous tasks". Async/await >> is just 'syntactic sugar' where the compiler re-writes your code into >> a state machine around APM (Asynchronous programming model which was >> introduced in .NET 2.0 sometime around 2002 I believe). That's all >> there is to it, it makes your asynchronous code look and feel >> synchronous. The only parts of Async/Await that have anything to do with APM are the interop stubs. C#'s Async/Await is built around the Task Asynchronous Programming model (e.g. Task and Task<T>) the compiler lowers to those, not APM. A common misunderstanding is that Task/Task<T> is based on APM, it's not, Task uses fundamentally different code underneath. On Linux/macOS it actually uses libuv (at the end of the day all of these programming models are callback based). Yes, C#'s async design does make code look and feel synchronous, and it was intentionally designed that way, but that is not *why* they did Async. That misunderstanding arises from an interview that Anders did in which he was asked why they held Async back for three years after announcing it at PDC08. In that same talk Anders specifically says that the purpose of the Async is to free up threads to continue execution, his example is a Windows Desktop Message Pump and fetching pictures from the internet (long-wait IO), but the principal applies to any thread. They held back async for three years because they needed to refine the language syntax to something that people could learn and apply in a reasonable amount of time. IIRC there is a Channel9 video where Anders explains the evolution of Async Await. Source: I was at Build 2011 and sat in on the Anders Hejlsberg (C# language designer) and Stephen Toub (Async/Await implementer) talks where they discussed Async in detail. I also work for MSFT, I can email them directly if you want further clarification on anything. :) -- Adam Wilson IRC: LightBender import quiet.dlang.dev; | |||
October 24, 2017 Re: My two cents | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Adam Wilson | On Tuesday, 24 October 2017 at 04:26:42 UTC, Adam Wilson wrote: > On 10/23/17 17:27, flamencofantasy wrote: >> On Monday, 23 October 2017 at 22:22:55 UTC, Adam Wilson wrote: >>> On 10/23/17 08:21, Kagamin wrote: >>>> [...] >>> >>> Actually I think it fits perfectly with D, not for reason of >>> performance, but for reason of flexibility. D is a polyglot language, >>> with by far the most number of methodologies supported in a single >>> language that I've ever encountered. >>> >>> [...] >> >> There is a lot of misunderstanding about async/await. It has nothing to >> do with "conservation of thread resources" or trading "raw performance >> for an ability >>> to handle a truly massive number of simultaneous tasks". Async/await >>> is just 'syntactic sugar' where the compiler re-writes your code into >>> a state machine around APM (Asynchronous programming model which was >>> introduced in .NET 2.0 sometime around 2002 I believe). That's all >>> there is to it, it makes your asynchronous code look and feel >>> synchronous. > > > The only parts of Async/Await that have anything to do with APM are the interop stubs. C#'s Async/Await is built around the Task Asynchronous Programming model (e.g. Task and Task<T>) the compiler lowers to those, not APM. A common misunderstanding is that Task/Task<T> is based on APM, it's not, Task uses fundamentally different code underneath. On Linux/macOS it actually uses libuv (at the end of the day all of these programming models are callback based). > I’ll throw in my 2 rubbles. I actually worked on a VM that has async/await feature built-in (Dart language). It is a plain syntax sugar for Future/Promise explicit asynchrony where async automatically return Future[T] or Observable[T] (the latter is async stream). Async function with awaits is then re-written as a single call-back with a basic state machine, each state corresponds to the line where you did await. Example: async double calculateTax(){ double taxRate = await getTaxRates(); double income = await getIncome(); return taxRate * income; } Becomes roughly this (a bit more mechanical though): Future!double calculateTax(){ int state = 0; Promise!double __ret; double taxRate; double income; void cb() { if(state == 0) { state = 1; getTaxRates().andThen((double ret){ taxRate = ret; cb(); }); } else if (state == 1) { state = 2; getIncome().andThen((double ret){ income = ret; cb(); }); else if (state == 2){ __ret.resolve(taxRate*income); } } cb(); } It doesn’t matter what mechanics you use to complete promises - be it IO scheduler a-la libuv or something else. Async/await is agnostic to that. Still there is a fair amount of machinery to hide the rewrite from the user and in particular print stack trace as if it was normal sequential code. > Yes, C#'s async design does make code look and feel synchronous, and it was intentionally designed that way, but that is not *why* they did Async. That misunderstanding arises from an interview that Anders did in which he was asked why they held Async back for three years after announcing it at PDC08. In that same talk Anders specifically says that the purpose of the Async is to free up threads to continue execution, his example is a Windows Desktop Message Pump and fetching pictures from the internet (long-wait IO), but the principal applies to any thread. They held back async for three years because they needed to refine the language syntax to something that people could learn and apply in a reasonable amount of time. IIRC there is a Channel9 video where Anders explains the evolution of Async Await. In other words - explicit asynchrony where a thread immediately returns with Future[T] and moves on to the next task. It’s just hidden by Async/Await. | |||
October 23, 2017 Re: My two cents | ||||
|---|---|---|---|---|
| ||||
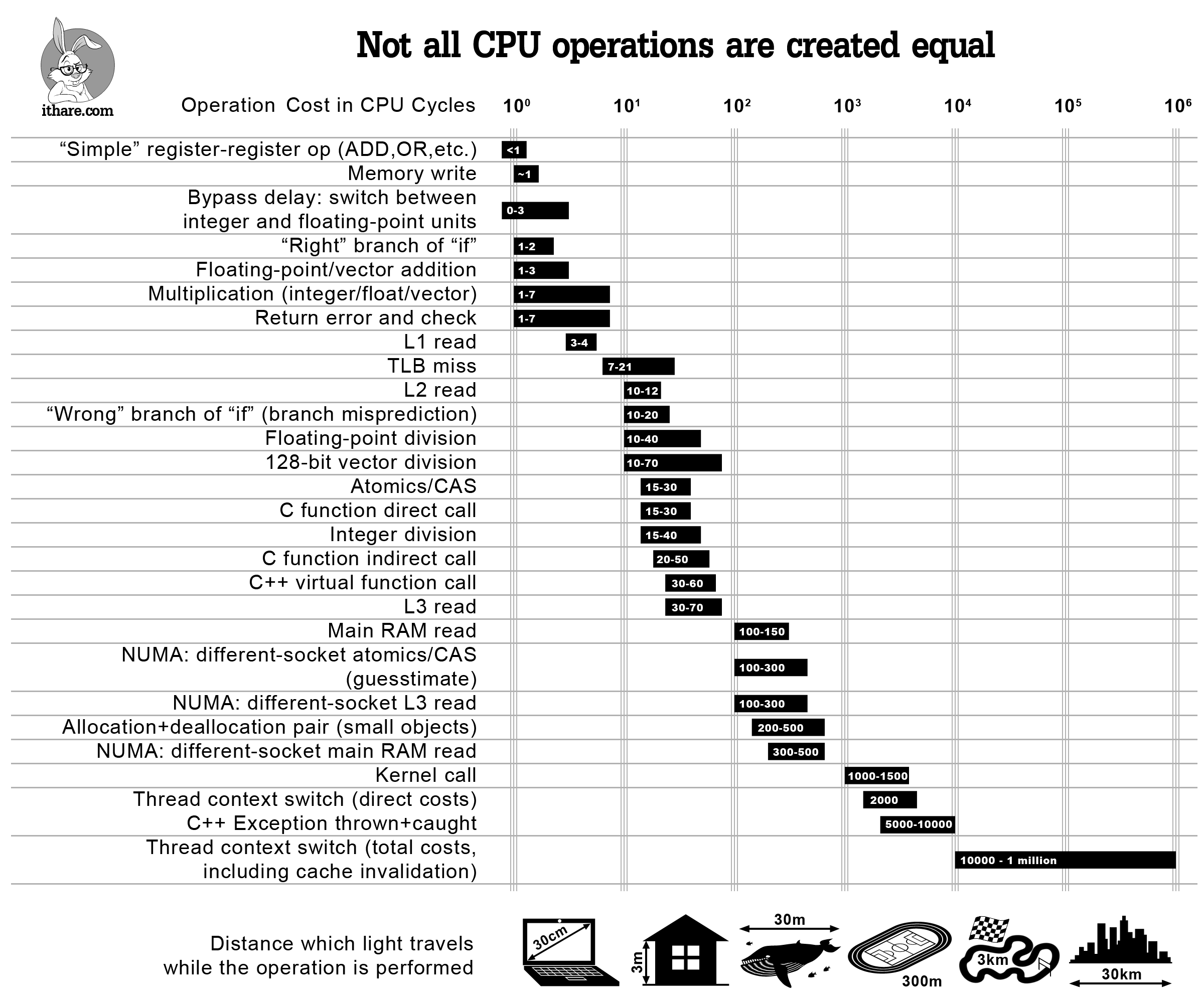
Posted in reply to Nathan S. | On 10/23/17 16:47, Nathan S. wrote: > On Monday, 23 October 2017 at 22:22:55 UTC, Adam Wilson wrote: >> Additionally, MSFT/C# fully recognizes that the benefits of >> Async/Await have never been and never were intended to be for >> performance. Async/Await trades raw performance for an ability to >> handle a truly massive number of simultaneous tasks. > > Could you clarify this? Do you mean it's not supposed to have better > performance for small numbers of tasks, but there is supposed to be some > high threshold of tasks/second at which either throughput or latency is > better? It's pretty complicated. In general, for a small number of tasks, it will take longer to execute those task with Async than without (Async has an overhead, about 10ms IIRC). So each individual call to an awaitable function will take longer than a call to a blocking function. In fact, MSFT recommends that if you are reasonably certain that most of the time it will take less than about 10ms to just use the blocking methods, as they have less total overhead. The main benefit of Async is in throughput. It allows the physical CPU to handle many incoming requests. So while each individual request may take longer, the overall utilization of the CPU is much higher. Async, has different benefits and drawbacks depending on where it's applied. For example, in UI apps, it allows the main program thread to keep responding to system events while waiting for long-wait IO (the thread is not suspended). Some background that may help understanding is that in blocking IO, what is really happening underneath your blocking call is that the runtime is creating a callback and then calling the OS's thread suspend method (e.g. ThreadSuspend in Windows), then when the callback is called, the thread is resumed and the data passed to into it via the callback. This means that the calling thread cannot execute anything while it's waiting. This is why UX apps appear to freeze when using blocking IO calls. The reason this is done is because the application has no way to say "I'm going to put this task off to the side and keep executing". The thread does not know to start some other processing while waiting. Async allows the app to put that task to the aside and do something else. At a low level the process in .NET it does this by: 1. Serializing the stack frame of the currently executing method to the heap (yes, Async is a GC feature, just like lambdas) at an await. 2. Pulling the next completed task from the heap. 3. Rebuilding the stack frame for that method on any available thread. 4. Continue execution of that stack. Obviously this makes a lot of sense for UI apps, where blocking the main thread can be disastrous, but why internet applications are inherently multi-threaded, so why do we care? The answer is thread context switching. A context switch is the most expensive common CPU operation by an order of magnitude, ranging from 2k-1m cycles. Whereas on modern CPUs a main RAM read is 100-150 cycles and a NUMA different socket read is 300-500 cycles. In .NET the TaskScheduler creates a predetermined number of threads (one per core IIRC) and begins scheduling tasks on those threads. Remembering that each task is really just a block on the heap, in the worst case that will take 500 cycles. Whereas if we had to switch to a different thread, it could be up to 1m cycles. That is a noticeable difference. Context switches are painfully expensive but in the traditional model it was all we had. Task based systems allow us to circumvent the task switch. But they're cumbersome to use without compiler support. For example, the Task Parallel Library was added in .NET 4.0 which includes Task and Task<T> and ALL of the constructs that are used in Async/Await, however, it was not until .NET 4.5 and the arrival of the Async/Await keywords (and the compiler lowerings that they enabled) that people started using Tasks in any significant way. (Source for access times: http://ithare.com/wp-content/uploads/part101_infographics_v08.png) -- Adam Wilson IRC: LightBender import quiet.dlang.dev; | |||
{kind=link}
October 23, 2017 Re: My two cents | ||||
|---|---|---|---|---|
| ||||
Posted in reply to Dmitry Olshansky | On 10/23/17 22:40, Dmitry Olshansky wrote: > On Tuesday, 24 October 2017 at 04:26:42 UTC, Adam Wilson wrote: >> On 10/23/17 17:27, flamencofantasy wrote: >>> On Monday, 23 October 2017 at 22:22:55 UTC, Adam Wilson wrote: >>>> On 10/23/17 08:21, Kagamin wrote: >>>>> [...] >>>> >>>> Actually I think it fits perfectly with D, not for reason of >>>> performance, but for reason of flexibility. D is a polyglot language, >>>> with by far the most number of methodologies supported in a single >>>> language that I've ever encountered. >>>> >>>> [...] >>> >>> There is a lot of misunderstanding about async/await. It has nothing to >>> do with "conservation of thread resources" or trading "raw performance >>> for an ability >>>> to handle a truly massive number of simultaneous tasks". Async/await >>>> is just 'syntactic sugar' where the compiler re-writes your code into >>>> a state machine around APM (Asynchronous programming model which was >>>> introduced in .NET 2.0 sometime around 2002 I believe). That's all >>>> there is to it, it makes your asynchronous code look and feel >>>> synchronous. >> >> >> The only parts of Async/Await that have anything to do with APM are >> the interop stubs. C#'s Async/Await is built around the Task >> Asynchronous Programming model (e.g. Task and Task<T>) the compiler >> lowers to those, not APM. A common misunderstanding is that >> Task/Task<T> is based on APM, it's not, Task uses fundamentally >> different code underneath. On Linux/macOS it actually uses libuv (at >> the end of the day all of these programming models are callback based). >> > > I’ll throw in my 2 rubbles. > > I actually worked on a VM that has async/await feature built-in (Dart > language). > It is a plain syntax sugar for Future/Promise explicit asynchrony where > async automatically return Future[T] or Observable[T] (the latter is > async stream). > > Async function with awaits is then re-written as a single call-back with > a basic state machine, each state corresponds to the line where you did > await. > > Example: > > async double calculateTax(){ > double taxRate = await getTaxRates(); > double income = await getIncome(); > return taxRate * income; > } > > Becomes roughly this (a bit more mechanical though): > > Future!double calculateTax(){ > int state = 0; > Promise!double __ret; > double taxRate; > double income; > void cb() { > if(state == 0) { > state = 1; > getTaxRates().andThen((double ret){ > taxRate = ret; > cb(); > }); > } > else if (state == 1) { > state = 2; > getIncome().andThen((double ret){ > income = ret; > cb(); > }); > else if (state == 2){ > __ret.resolve(taxRate*income); > } > } > cb(); > } > > It doesn’t matter what mechanics you use to complete promises - be it IO > scheduler a-la libuv or something else. Async/await is agnostic to that. > That was actually my point. Windows and Linux/macOS .NET core do different things. It doesn't matter to the dev. You did a better job of illuminating it. :) > Still there is a fair amount of machinery to hide the rewrite from the > user and in particular print stack trace as if it was normal sequential > code. > And that is the difficulty we face in D. :) > >> Yes, C#'s async design does make code look and feel synchronous, and >> it was intentionally designed that way, but that is not *why* they did >> Async. That misunderstanding arises from an interview that Anders did >> in which he was asked why they held Async back for three years after >> announcing it at PDC08. In that same talk Anders specifically says >> that the purpose of the Async is to free up threads to continue >> execution, his example is a Windows Desktop Message Pump and fetching >> pictures from the internet (long-wait IO), but the principal applies >> to any thread. They held back async for three years because they >> needed to refine the language syntax to something that people could >> learn and apply in a reasonable amount of time. IIRC there is a >> Channel9 video where Anders explains the evolution of Async Await. > > In other words - explicit asynchrony where a thread immediately returns > with Future[T] and moves on to the next task. It’s just hidden by > Async/Await. > Yup. -- Adam Wilson IRC: LightBender import quiet.dlang.dev; | |||
October 24, 2017 Re: My two cents | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Igor | 23.10.2017 23:25, Igor пишет:
> On Monday, 23 October 2017 at 11:02:41 UTC, Martin Nowak wrote:
>>
>> In C++ incremental rebuilds are simple as you compile each file individually anyhow, but that's the crux for why C++ compilations are so slow in the first place.
>> Compiling multiple modules at once provides lots of speedups as you do not have to reparse and analyze common/mutual imports, but on the downside it cannot be parallelized that well.
>>
>
> I wish I knew how Delphi was compiling things because it is by far the fastest compiler I have ever tried. It compiled individual files as well but not into obj files but some dcu files and it used them if source wasn't changed when compiling sources that depended on that module.
Yeah, in time of Delphi 6 I thought that Delphi wasn't as serious as C++ (don't remember compiler version exactly) because Delphi compiles so fast comparing to C++. C++ was cool that time in my eyes because I can see it was doing something cool and of course very serious)) Delphi was really as fast as lightning and it was not interesting.
| |||
October 24, 2017 Re: My two cents | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Atila Neves | On Monday, 23 October 2017 at 21:42:03 UTC, Atila Neves wrote:
> On Monday, 23 October 2017 at 21:14:18 UTC, bauss wrote:
>> On Monday, 23 October 2017 at 12:48:33 UTC, Atila Neves wrote:
>>> On Monday, 23 October 2017 at 09:13:45 UTC, Satoshi wrote:
>>>> On Wednesday, 18 October 2017 at 08:56:21 UTC, Satoshi wrote:
>>>>> [...]
>>>>
>>>> Whats about this one?
>>>>
>>>> auto foo = 42;
>>>> auto bar = "bar";
>>>> writeln(`Foo is {foo} and bar is {bar}`);
>>>
>>> writeln("Foo is ", foo, "and bar is ", bar");
>>>
>>> Two more characters.
>>>
>>> Atila
>>
>> Okay, but what about now?
>>
>> void sendAMessage(string message)
>> {
>> ....
>> }
>
> sendAMessage(text(...));
>
> Atila
boilerplate...
| |||
October 24, 2017 Re: My two cents | ||||
|---|---|---|---|---|
| ||||
Posted in reply to Walter Bright | On Monday, 23 October 2017 at 20:47:26 UTC, Walter Bright wrote:
> On 10/18/2017 1:56 AM, Satoshi wrote:
>> Unable to publish closed source library without workaround and ugly PIMPL design.
>
>
> Consider this:
>
> ----------- file s.d ------------
> struct S {
> int x;
> this(int x) { this.x = x; }
> int getX() { return x; }
> }
> ----------- file s.di ------------
> struct S {
> this(int x);
> int getX();
> }
> --------------------------
>
> User code:
>
> import s;
> S s = S(3);
> writeln(s.getX());
>
> Ta dah! Implementation is hidden, no PIMPL. Of course, inlining of the member functions won't work, but it won't work in C++, either, when this technique is used.
>
> I.e. you can use .di/.d files just like you'd use .h/.cpp in C++. The technique works with classes, too.
what about this:
---------- file.d
class Foo {
private int bar;
private string text;
void call() { }
}
----------- file.di
class Foo {
call();
}
and then I want to inherit from it (I have access to file.di only)
class Bar : Foo { // I cannot due I have misleading information about size of Foo
}
| |||
October 24, 2017 Re: My two cents | ||||
|---|---|---|---|---|
| ||||
Posted in reply to Kagamin | On Monday, 23 October 2017 at 15:21:02 UTC, Kagamin wrote:
> On Friday, 20 October 2017 at 09:49:34 UTC, Adam Wilson wrote:
>> Others are less obvious, for example, async/await is syntax sugar for a collection of Task-based idioms in C#.
>
> Now I think it's doesn't fit D. async/await wasn't made for performance, but for conservation of thread resources, async calls are rather expensive, which doesn't fit in D if we prefer raw performance. Also I found another shortcoming: it doesn't interoperate well with cache: cache flip flops between synchronous and asynchronous operation: when you hit cache it's synchronous, when you miss it it performs IO.
Actually, async/await should be faster and safer than running same blocking code in another thread and then syncing between them.
If we want to use D for GUI development we will need this feature anyway. It's the easiest solution how to run blocking functions in GUI callback without freezing, it reduces bugs and callback hell. Look at Javascript and Node.js (I think).
| |||
October 24, 2017 Re: My two cents | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Atila Neves | On Monday, 23 October 2017 at 12:48:33 UTC, Atila Neves wrote:
> On Monday, 23 October 2017 at 09:13:45 UTC, Satoshi wrote:
>> writeln(`Foo is {foo} and bar is {bar}`);
>
> writeln("Foo is ", foo, "and bar is ", bar");
>
> Two more characters.
You have actually demonstrates exactly what I feel is the main benefit of the "{foo}" syntax: Your example is missing a space before 'and'. This type of error is very easy to overlook with the ", " syntax, and much more visible with the "{foo}" syntax. The "%s" syntax also solves this problem, but at the cost of moving the formatted value away from the point of formatting.
--
Biotronic
| |||
Copyright © 1999-2021 by the D Language Foundation