
October 04, 2013 Re: std.d.lexer performance (WAS: std.d.lexer : voting thread) | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Andrei Alexandrescu | On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote: > I see we're considerably behind dmd. If improving performance would come at the price of changing the API, it may be sensible to hold off adoption for a bit. > > Andrei The old benchmarks measured total program run time. I ran a new set of benchmarks, placing stopwatch calls around just the lexing code to bypass any slowness caused by druntime startup. I also made a similar modification to DMD. Here's the result: https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times5.png I suspect that I've made an error in the benchmarking due to how much faster std.d.lexer is than DMD now, so I've uploaded what I have to Github. https://github.com/Hackerpilot/lexerbenchmark | |||
 Permalink
Permalink Reply
Reply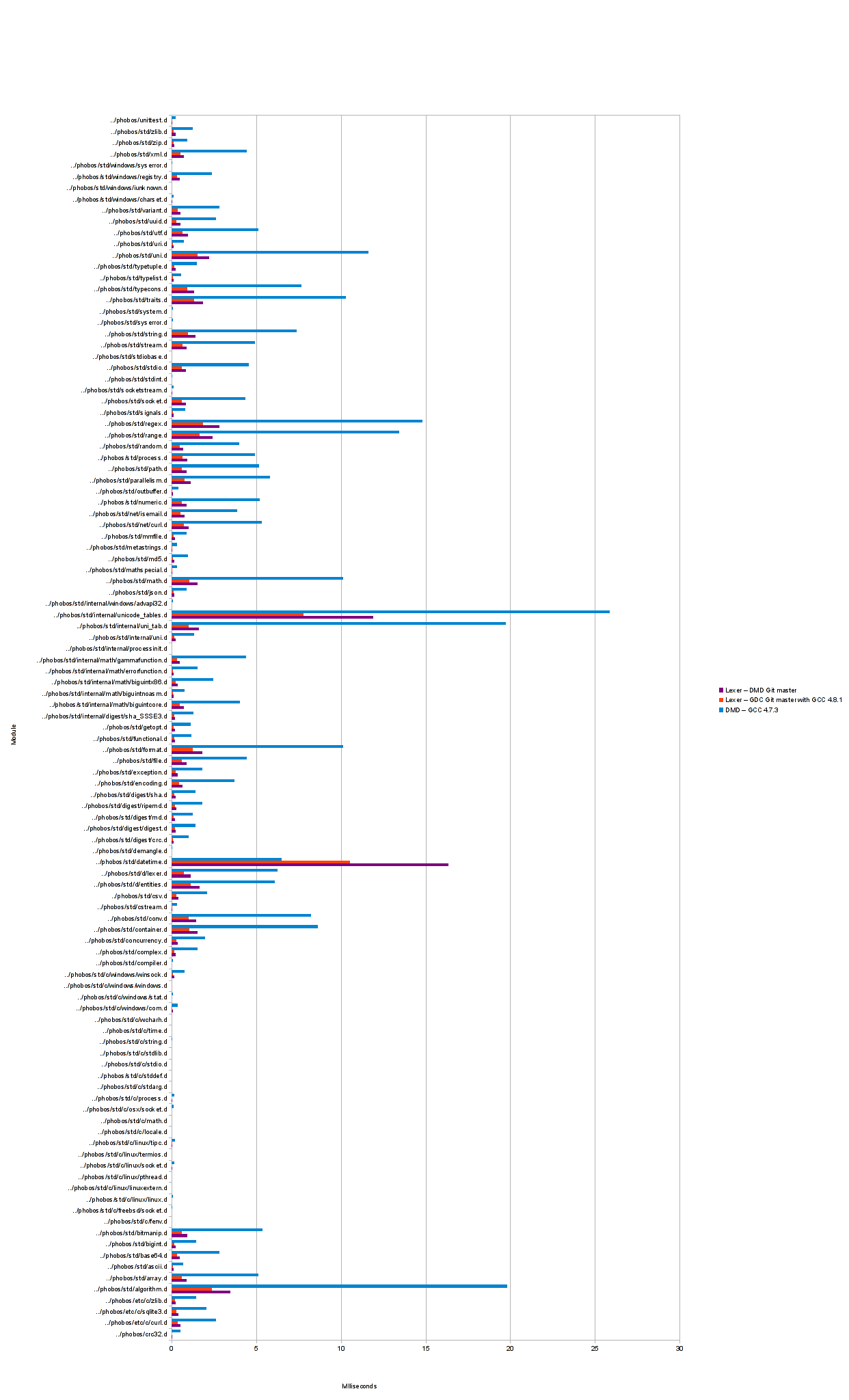{kind=link}
October 04, 2013 Re: std.d.lexer performance (WAS: std.d.lexer : voting thread) | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Brian Schott | On 2013-10-04 13:28, Brian Schott wrote: > Here's the result: > > https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times5.png > > > I suspect that I've made an error in the benchmarking due to how much > faster std.d.lexer is than DMD now, so I've uploaded what I have to Github. > > https://github.com/Hackerpilot/lexerbenchmark If these results are correct, me like :) -- /Jacob Carlborg | |||
October 04, 2013 Re: std.d.lexer performance (WAS: std.d.lexer : voting thread) | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Brian Schott | Brian Schott wrote:
> On Thursday, 3 October 2013 at 20:11:02 UTC, Andrei Alexandrescu wrote:
>> I see we're considerably behind dmd. If improving performance would
>> come at the price of changing the API, it may be sensible to hold off
>> adoption for a bit.
>>
>> Andrei
>
> The old benchmarks measured total program run time. I ran a new set of
> benchmarks, placing stopwatch calls around just the lexing code to
> bypass any slowness caused by druntime startup. I also made a similar
> modification to DMD.
>
> Here's the result:
>
> https://raw.github.com/Hackerpilot/hackerpilot.github.com/master/experimental/std_lexer/images/times5.png
>
>
> I suspect that I've made an error in the benchmarking due to how much
> faster std.d.lexer is than DMD now, so I've uploaded what I have to Github.
>
> https://github.com/Hackerpilot/lexerbenchmark
Interestingly, DMD is only faster when lexing std.datetime. This is relatively big file, so maybe the slowness is related to small buffering in std.d.lexer?
| |||
October 04, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to ilya-stromberg | On Friday, 4 October 2013 at 09:41:49 UTC, ilya-stromberg wrote: > On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote: >> After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos. > > No. > > I really want to see `std.d.lexer` in Phobos, but have too many conditions. > > Documentation issues: > clip > > - please add more usage examples. Currently you have only one big example how generate HTML markup of D code. Try to add a simple example for every function. > clip Woah! A simple example for every function? Then it would put the rest of the Phobos documents to shame :o) | |||
October 04, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Craig Dillabaugh | On Friday, 4 October 2013 at 14:30:12 UTC, Craig Dillabaugh wrote:
> On Friday, 4 October 2013 at 09:41:49 UTC, ilya-stromberg wrote:
>> On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:
>>> After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.
>>
>> No.
>>
>> I really want to see `std.d.lexer` in Phobos, but have too many conditions.
>>
>> Documentation issues:
>>
> clip
>>
>> - please add more usage examples. Currently you have only one big example how generate HTML markup of D code. Try to add a simple example for every function.
>>
> clip
>
> Woah! A simple example for every function? Then it would put the rest of the Phobos documents to shame :o)
I said: "TRY to add". But yes, I feel that `std.d.lexer` don't have enough documentation.
| |||
October 04, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Craig Dillabaugh | On Fri, Oct 04, 2013 at 04:30:11PM +0200, Craig Dillabaugh wrote: > On Friday, 4 October 2013 at 09:41:49 UTC, ilya-stromberg wrote: [...] > >- please add more usage examples. Currently you have only one big example how generate HTML markup of D code. Try to add a simple example for every function. > > > clip > > Woah! A simple example for every function? Then it would put the rest of the Phobos documents to shame :o) The rest of Phobos docs *should* be put to shame. Except maybe for a few exceptions here and there, most of Phobos docs are far too scant, and need some serious TLC with many many more code examples. T -- Customer support: the art of getting your clients to pay for your own incompetence. | |||
October 04, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to Craig Dillabaugh | On 10/4/13 7:30 AM, Craig Dillabaugh wrote:
> On Friday, 4 October 2013 at 09:41:49 UTC, ilya-stromberg wrote:
>> On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:
>>> After brief discussion with Brian and gathering data from the review
>>> thread, I have decided to start voting for `std.d.lexer` inclusion
>>> into Phobos.
>>
>> No.
>>
>> I really want to see `std.d.lexer` in Phobos, but have too many
>> conditions.
>>
>> Documentation issues:
>>
> clip
>>
>> - please add more usage examples. Currently you have only one big
>> example how generate HTML markup of D code. Try to add a simple
>> example for every function.
>>
> clip
>
> Woah! A simple example for every function? Then it would put the
> rest of the Phobos documents to shame :o)
I would say matters that are passable for now and easy to improve later without disruption don't necessarily preclude approval.
Andrei
| |||
October 04, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
Posted in reply to ilya-stromberg | On Friday, 4 October 2013 at 16:03:25 UTC, ilya-stromberg wrote:
> On Friday, 4 October 2013 at 14:30:12 UTC, Craig Dillabaugh wrote:
>> On Friday, 4 October 2013 at 09:41:49 UTC, ilya-stromberg wrote:
>>> On Wednesday, 2 October 2013 at 14:41:56 UTC, Dicebot wrote:
>>>> After brief discussion with Brian and gathering data from the review thread, I have decided to start voting for `std.d.lexer` inclusion into Phobos.
>>>
>>> No.
>>>
>>> I really want to see `std.d.lexer` in Phobos, but have too many conditions.
>>>
>>> Documentation issues:
>>>
>> clip
>>>
>>> - please add more usage examples. Currently you have only one big example how generate HTML markup of D code. Try to add a simple example for every function.
>>>
>> clip
>>
>> Woah! A simple example for every function? Then it would put the rest of the Phobos documents to shame :o)
>
> I said: "TRY to add". But yes, I feel that `std.d.lexer` don't have enough documentation.
I think it was a good idea ... it just sort of jumped out at me as the Phobos documentation tends to be missing lots of examples. Thus the smiley on the end.
| |||
October 04, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
 Posted in reply to David Nadlinger | I created https://github.com/phobos-x/phobosx for this, it is also in the dub registry. It could be used, until something more official is established. Best regards, Robert On Fri, 2013-10-04 at 05:29 +0200, David Nadlinger wrote: > On Friday, 4 October 2013 at 02:57:41 UTC, Martin Nowak wrote: > > Adding it as experimental module would be a good idea. > > I would be in favor of adding such community-reviewed but not-quite-there-yet libraries to a special category on the DUB registry instead. > > It would also solve the visibility problem, and apart from the fact that it isn't really clear what being an »experimental« module would entail, having it as a package also allows for faster updates not reliant on the core release schedule. > > David | |||
October 05, 2013 Re: std.d.lexer : voting thread | ||||
|---|---|---|---|---|
| ||||
Posted in reply to Dicebot | On 10/2/13 7:41 AM, Dicebot wrote: > After brief discussion with Brian and gathering data from the review > thread, I have decided to start voting for `std.d.lexer` inclusion into > Phobos. Thanks all involved for the work, first of all Brian. I have the proverbial good news and bad news. The only bad news is that I'm voting "no" on this proposal. But there's plenty of good news. 1. I am not attempting to veto this, so just consider it a normal vote when tallying. 2. I do vote for inclusion in the /etc/ package for the time being. 3. The work is good and the code valuable, so even in the case my suggestions (below) will be followed, a virtually all code pulp that gets work done can be reused. Vision ====== I'd been following the related discussions for a while, but I have made up my mind today as I was working on a C++ lexer today. The C++ lexer is for Facebook's internal linter. I'm translating the lexer from C++. Before long I realized two simple things. First, I can't reuse anything from Brian's code (without copying it and doing surgery on it), although it is extremely similar to what I'm doing. Second, I figured that it is almost trivial to implement a simple, generic, and reusable (across languages and tasks) static trie searcher that takes a compile-time array with all tokens and keywords and returns the token at the front of a range with minimum comparisons. Such a trie searcher is not intelligent, but is very composable and extremely fast. It is just smart enough to do maximum munch (e.g. interprets "==" and "foreach" as one token each, not two), but is not smart enough to distinguish an identifier "whileTrue" from the keyword "while" (it claims "while" was found and stops right at the beginning of "True" in the stream). This is for generality so applications can define how identifiers work (e.g. Lisp allows "-" in identifiers but D doesn't etc). The trie finder doesn't do numbers or comments either. No regexen of any kind. The beauty of it all is that all of these more involved bits (many of which are language specific) can be implemented modularly and trivially as a postprocessing step after the trie finder. For example the user specifies "/*" as a token to the trie finder. Whenever a comment starts, the trie finder will find and return it; then the user implements the alternate grammar of multiline comments. To encode the tokens returned by the trie, we must do away with definitions such as enum TokenType : ushort { invalid, assign, ... } These are fine for a tokenizer written in C, but are needless duplication from a D perspective. I think a better approach is: struct TokenType { string symbol; ... } TokenType tok(string s)() { static immutable string interned = s; return TokenType(interned); } Instead of associating token types with small integers, we associate them with string addresses. (For efficiency we may use pointers to zero-terminated strings, but I don't think that's necessary). Token types are interned by design, i.e. to compare two tokens for equality it suffices to compare the strings with "is" (this can be extended to general identifiers, not only statically-known tokens). Then, each token type has a natural representation that doesn't require the user to remember the name of the token. The left shift token is simply tok!"<<" and is application-global. The static trie finder does not even build a trie - it simply generates a bunch of switch statements. The signature I've used is: Tuple!(size_t, size_t, Token) staticTrieFinder(alias TokenTable, R)(R r) { It returns a tuple with (a) whitespace characters before token, (b) newlines before token, and (c) the token itself, returned as tok!"whatever". To use for C++: alias CppTokenTable = TypeTuple!( "~", "(", ")", "[", "]", "{", "}", ";", ",", "?", "<", "<<", "<<=", "<=", ">", ">>", ">>=", "%", "%=", "=", "==", "!", "!=", "^", "^=", "*", "*=", ":", "::", "+", "++", "+=", "&", "&&", "&=", "|", "||", "|=", "-", "--", "-=", "->", "->*", "/", "/=", "//", "/*", "\\", ".", "'", "\"", "#", "##", "and", "and_eq", "asm", "auto", ... ); Then the code uses staticTrieFinder!([CppTokenTable])(range). Of course, it's also possible to define the table itself as an array. I'm exploring right now in search for the most advantageous choices. I think the above would be a true lexer in the D spirit: - exploits D's string templates to essentially define non-alphanumeric symbols that are easy to use and understand, not confined to predefined tables (that enum!) and cheap to compare; - exploits D's code generation abilities to generate really fast code using inlined trie searching; - offers and API that is generic, flexible, and infinitely reusable. If what we need at this point is a conventional lexer for the D language, std.d.lexer is the ticket. But I think it wouldn't be difficult to push our ambitions way beyond that. What say you? Andrei | |||
Copyright © 1999-2021 by the D Language Foundation